Helm Chart Request Entity Too Massive: Troubleshooting and Mitigation Methods
Associated Articles: Helm Chart Request Entity Too Massive: Troubleshooting and Mitigation Methods
Introduction
On this auspicious event, we’re delighted to delve into the intriguing subject associated to Helm Chart Request Entity Too Massive: Troubleshooting and Mitigation Methods. Let’s weave attention-grabbing info and provide contemporary views to the readers.
Desk of Content material
Helm Chart Request Entity Too Massive: Troubleshooting and Mitigation Methods

Deploying purposes by way of Helm charts streamlines the method, providing a declarative approach to handle Kubernetes sources. Nevertheless, even this elegant resolution can encounter irritating errors. One such error, "request entity too massive," typically stems from exceeding the scale limits imposed by the Kubernetes API server or middleman proxies. This text delves into the foundation causes of this error, offers sensible troubleshooting steps, and explores efficient mitigation methods to forestall future occurrences.
Understanding the Error:
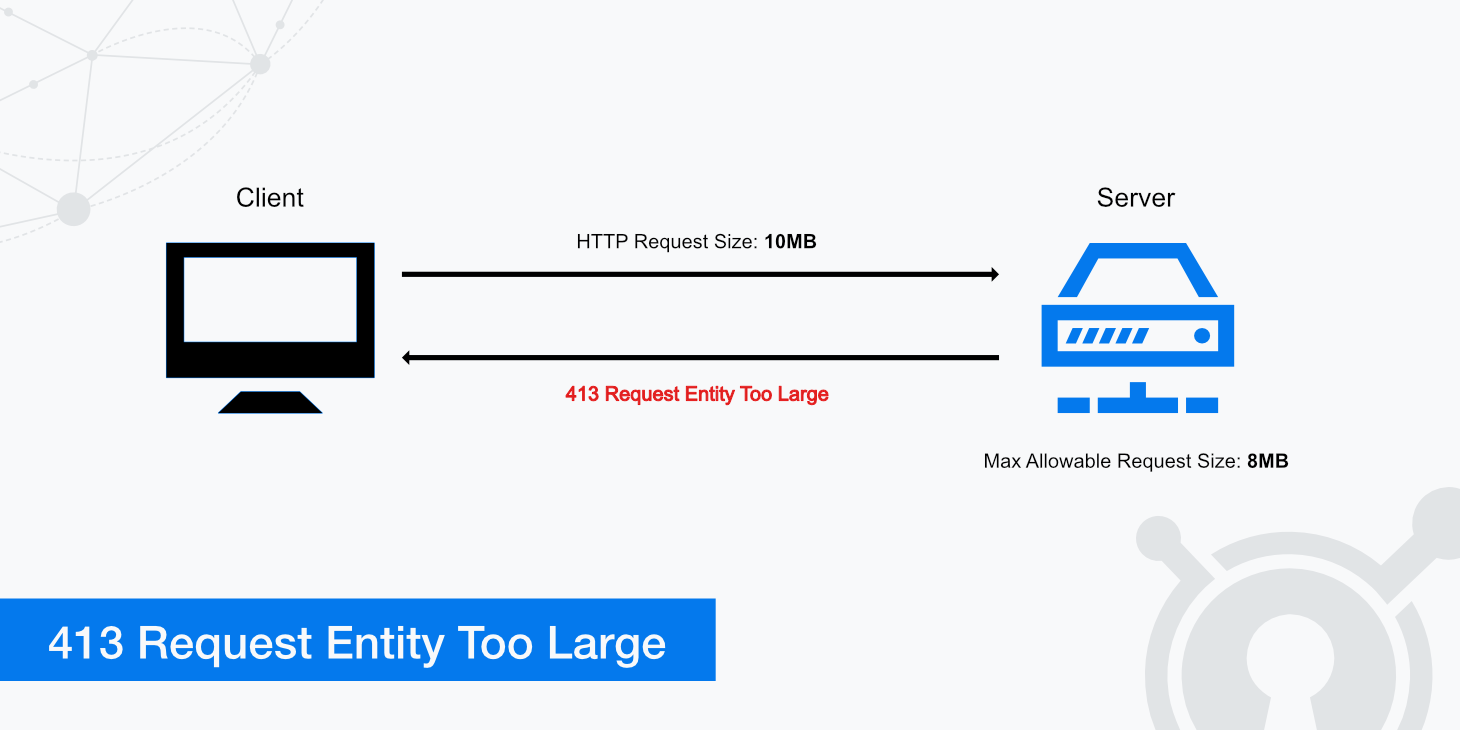
The "request entity too massive" error signifies that the HTTP request despatched to the Kubernetes API server making an attempt to deploy your Helm chart exceeds the server’s outlined restrict for the scale of the request physique. This restrict is often configured to forestall denial-of-service (DoS) assaults and to take care of system stability. Exceeding this restrict leads to a HTTP 413 error, successfully halting the Helm deployment.
Frequent Causes:
A number of elements can contribute to exceeding the request entity dimension restrict:
-
Massive Helm Charts: Charts containing quite a few sources, in depth configuration information, or massive volumes of information inside ConfigMaps and Secrets and techniques can shortly inflate the scale of the deployment request. Complicated purposes with many microservices or these incorporating substantial configuration knowledge are notably weak.
-
Extreme Values Information: Overly massive or deeply nested
values.yamlinformation, particularly when utilizing templating to generate in depth configurations, can considerably improve the request dimension. Pointless duplication or inefficient knowledge constructions inside the values file contribute to this drawback. -
Massive ConfigMaps and Secrets and techniques: Storing massive quantities of information instantly inside ConfigMaps and Secrets and techniques, equivalent to massive configuration information, photos, or database dumps, instantly impacts the scale of the deployment request. Kubernetes is designed for managing metadata, not for storing massive binary information.
-
Nested Charts: Utilizing nested charts, whereas providing modularity, can inadvertently improve the general dimension of the deployment request if not fastidiously managed. Every nested chart contributes its personal sources and configurations to the ultimate request.
-
Proxy Server Limitations: Middleman proxies between your shopper and the Kubernetes API server may need their very own dimension limits. If the request exceeds these limits, the error can manifest even when the API server’s restrict is increased.
-
Inefficient Templating: Overly complicated or inefficient Go templating inside your Helm chart can result in the era of excessively massive configuration information, thus contributing to the request dimension drawback.
Troubleshooting Steps:
Earlier than implementing mitigation methods, it is essential to pinpoint the precise reason behind the massive request. Here is a step-by-step troubleshooting information:
-
Establish the Offender: Begin by analyzing the Helm chart’s construction. Analyze the scale of the person information inside the chart, paying specific consideration to
values.yaml, ConfigMaps, and Secrets and techniques. Use instruments likedu(disk utilization) to find out the scale of directories and information. -
Verify the API Server Limits: You possibly can examine the API server’s request dimension restrict utilizing the next command:
kubectl get configmap kube-proxy -n kube-system -o jsonpath='.knowledge.proxy-client-max-body-size'This command retrieves the
proxy-client-max-body-sizesetting from thekube-proxyconfigmap, which regularly dictates the request dimension restrict. If the restrict is low, take into account rising it (although this ought to be executed cautiously and with consciousness of safety implications). -
Study Proxy Server Configurations: When you’re utilizing a proxy server, examine its configuration for request dimension limits. Regulate these limits if crucial, however keep in mind to steadiness safety issues.
-
Analyze Helm Logs: Study the Helm logs for any clues in regards to the failed request. This would possibly present insights into the particular a part of the chart inflicting the difficulty.
-
Simplify the Chart: Briefly take away components of your chart to isolate the problematic element. This means of elimination can pinpoint the supply of the extreme dimension.
-
Optimize Values Information: Refactor your
values.yamlfile to take away pointless knowledge or use extra environment friendly knowledge constructions. Think about breaking down overly massive values information into smaller, extra manageable ones. -
Optimize ConfigMaps and Secrets and techniques: Keep away from storing massive binary information in ConfigMaps and Secrets and techniques. As a substitute, use Kubernetes persistent volumes (PVs) or cloud storage options for big datasets. For secrets and techniques, think about using devoted secret administration instruments like HashiCorp Vault or AWS Secrets and techniques Supervisor.
Mitigation Methods:
As soon as you have recognized the foundation trigger, implement the next methods to forestall future occurrences:
-
Refactor Massive Charts: Break down monolithic charts into smaller, extra manageable modules. This improves maintainability and reduces the scale of particular person deployment requests.
-
Optimize Values Information: Make use of methods like utilizing surroundings variables, exterior configuration information, or Kubernetes Secrets and techniques to handle configurations, lowering the scale of your
values.yamlfile. Use YAML anchors and aliases to keep away from redundancy. -
Externalize Massive Knowledge: Migrate massive knowledge from ConfigMaps and Secrets and techniques to exterior storage options like Persistent Volumes or cloud storage companies. Reference these exterior sources inside your chart utilizing applicable Kubernetes mechanisms.
-
Use Helm Hooks: Make the most of Helm hooks (e.g.,
post-install) to carry out duties like downloading massive information or configuring exterior sources after the preliminary deployment, thereby lowering the preliminary request dimension. -
Implement a Staging Course of: Make use of a staging surroundings to check deployments earlier than pushing them to manufacturing. This lets you determine and tackle dimension points early within the deployment lifecycle.
-
Enhance API Server Limits (Cautiously): Growing the API server’s request dimension restrict is a final resort. This ought to be executed solely after thorough consideration of safety implications and with the understanding that this would possibly have an effect on system stability.
-
Enhance Templating Effectivity: Evaluate your Go templating to make sure it is environment friendly and avoids pointless knowledge duplication. Use built-in features and filters to optimize the generated configuration information.
-
Make the most of Kustomize: Kustomize is a device that permits for customizing base YAML configurations with no need to change the unique information. This will help handle configurations extra successfully and scale back the scale of the ultimate deployment request.
Conclusion:
The "request entity too massive" error throughout Helm chart deployment is a standard drawback, however it’s typically preventable. By understanding the potential causes, diligently troubleshooting the difficulty, and implementing the mitigation methods outlined above, you may guarantee easy and environment friendly Helm deployments, even for complicated purposes. Do not forget that proactive design decisions, specializing in modularity, externalized configuration, and environment friendly useful resource administration, are key to avoiding this error in the long term. Repeatedly reviewing and optimizing your Helm charts will stop this situation from changing into a recurring bottleneck in your CI/CD pipeline.





Closure
Thus, we hope this text has supplied invaluable insights into Helm Chart Request Entity Too Massive: Troubleshooting and Mitigation Methods. We thanks for taking the time to learn this text. See you in our subsequent article!